Diese Website verwendet Cookies, damit wir dir die bestmögliche Benutzererfahrung bieten können. Cookie-Informationen werden in deinem Browser gespeichert und führen Funktionen aus, wie das Wiedererkennen von dir, wenn du auf unsere Website zurückkehrst, und hilft unserem Team zu verstehen, welche Abschnitte der Website für dich am interessantesten und nützlichsten sind.
Clusteranalyse
Clusteranalyse
Keine Kommentare
Mit Hilfe der Clusteranalyse kannst Du sogenannte „Untersuchungsobjekte“ zu Clustern bzw. natürlichen Gruppen zusammenfassen. Bei Untersuchungsobjekten kann es sich um Menschen, Unternehmen, Länder, etc. handeln, die aufgrund bestimmter Merkmale, wie persönliche Eigenschaften, Krankheitsbilder, Einkommen, usw., gruppiert werden. Ein gebildetes Cluster soll in sich maximal homogen sein, sich von den anderen Clustern aber gleichzeitig so stark wie möglich unterscheiden.
Die Clusteranalyse ist ein geeignetes Verfahren, wenn Du Strukturen in Deinem Datensatz untersuchen möchtest, inferenzstatische Aussagen kannst Du mit dieser Methode alleine aber keine treffen. Wenn Du bspw. herausfinden willst, ob Du alle Studiengänge einer Universität anhand der Anzahl an Studienanfängern, der durchschnittlichen Studiendauer und der Anzahl an praktischen Übungen gruppieren kannst, ist die Clusteranalyse die passende Methode.
Voraussetzungen für die Clusteranalyse
Deine Daten sollten die folgenden Kriterien erfüllen:
- Wenn Werte in Deinem Datensatz fehlen, musst Du ihn vor der Analyse bereinigen
- Die Stichprobe sollte nicht zu klein sein, wenn Du Aussagen über eine zugrundeliegende Population treffen möchtest
- Je nachdem mit welcher Software Du die Analyse durchführst, musst Du vorher die Skalenniveaus aller Deiner Variablen angleichen (generell unterliegst Du sonst aber keinerlei Einschränkungen bezüglich des Skalenniveaus)
- Unterscheiden sich die Variablen stark hinsichtlich ihres Wertebereichs, kann es zu aussagekräftigeren Ergebnissen führen, wenn Du die Variablen vor der Analyse z-transformierst
- Vor der Analyse solltest Du überprüfen, ob einzelne Objekte, im Vergleich zum Gesamtdatensatz, Extremwerte aufweisen, damit Dein Ergebnis nicht durch Ausreißer verzerrt wird
- Deine Variablen sollten nicht zu stark korrelliert sein, da das Ergebnis sonst ebenfalls stark verzerrt sein könnte.
Notwendige Parameter für die Clusteranalyse
Hast Du Deinen Datensatz hinsichtlich der Voraussetzungen überprüft, musst Du noch drei Entscheidungen treffen, bevor Du die Analyse durchführen kannst, damit Deine Statistiksoftware weiß, nach welchen Regeln sie die Objekte clustern soll. Diese Entscheidungen betreffen:
- Das Proximitätsmaß, d. h. Du musst bestimmen, wie die Distanz der Merkmale zwischen den einzelnen Untersuchungsobjekten ermittelt werden soll. Dieses Maß ist abhängig vom Skalenniveau der Daten und es gibt eine breitgefächerte Methodenauswahl. Für ein tiefgehendes Verständnis solltest Du Dich daher in entsprechende Literatur einarbeiten.
- Den Cluster-Alogrithmus, d. h. es liegt an Dir zu entscheiden, welches mathematische Verfahren angewandt wird, um Deine Daten in Clustern zu fusionieren. Auch hierbei steht Dir wieder ein breites Spektrum an Methoden zur Verfügung und Du solltest Dich gut mit der Materie vertraut machen, bevor Du einen Algorithmus auswählst.
- Die Anzahl der Cluster, d. h. Du solltest Dir inhaltlich genau überlegen, wie viele Cluster Du erwartest. Hierbei können Dir vor allem das Dendogramm, Fehlerquadratsummen und das Elbow-Kriterium als Entscheidungshilfen dienen. Allerdings erfordert deren Verständnis wieder eine vertiefte inhaltliche Auseinandersetzung.
Grafische Darstellung der Ergebnisse
Die Ergebnisse der Clusteranalyse werden häufig mit Hilfe eines Streudiagramms veranschaulicht. So kannst Du grafisch darstellen, wie viele Cluster Du extrahiert hast und wie Du diese inhaltlich interpretierst. Ein Ergebnis könnte bspw. folgendermaßen aussehen:
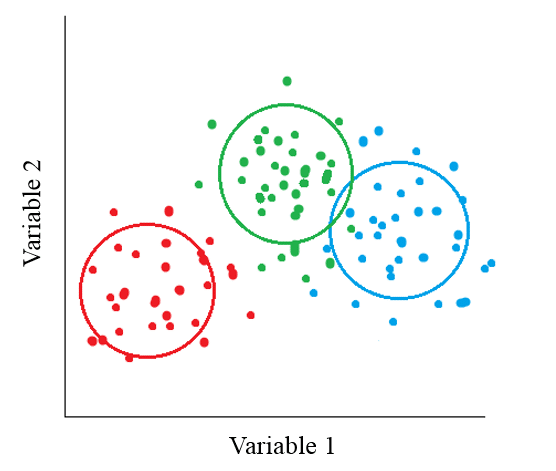
Wie Du siehst, würde die Datenwolke ohne Cluster auf den ersten Blick kein Muster aufweisen. Die Cluster-Analyse kann Dir also helfen Informationen sichtbar zu machen und zu gewinnen. Mit anderen Methoden wären sie Dir evtl. verborgen geblieben.
Bei der Ergebnisdarstellung solltest Du zudem immer angeben, welches Proximitätsmaß und welchen Cluster-Algorithmus Du verwendet hast. Denn das methodische Repertoire der Clusteranalyse ist extrem umfangreich. Außenstehende sollten schließlich Deine Analysen nachzuvollziehen können.
Um die einzelnen Cluster genauer zu beschreiben, werden in der Regel einfach ihre deskriptiven Daten herangezogen. Anhand derer kannst Du weitere Aussagen treffen, bspw. über die Mittelwerte der verschiedenen Cluster. Diese Mittelwerte kannst Du dann auch mit geeigneten Methoden (z. B. ANOVA) vergleichen und überprüfen, ob die Unterschiede signifikant sind.